Scientific literature understanding plays a pivotal role in uncovering knowledge structures that facilitate scientific discovery. Recent studies highlight the effectiveness of pre-trained language models in scientific literature understanding tasks, especially when tuned through contrastive learning. However, there is a gap in jointly utilizing data across different tasks for language model pre-training.
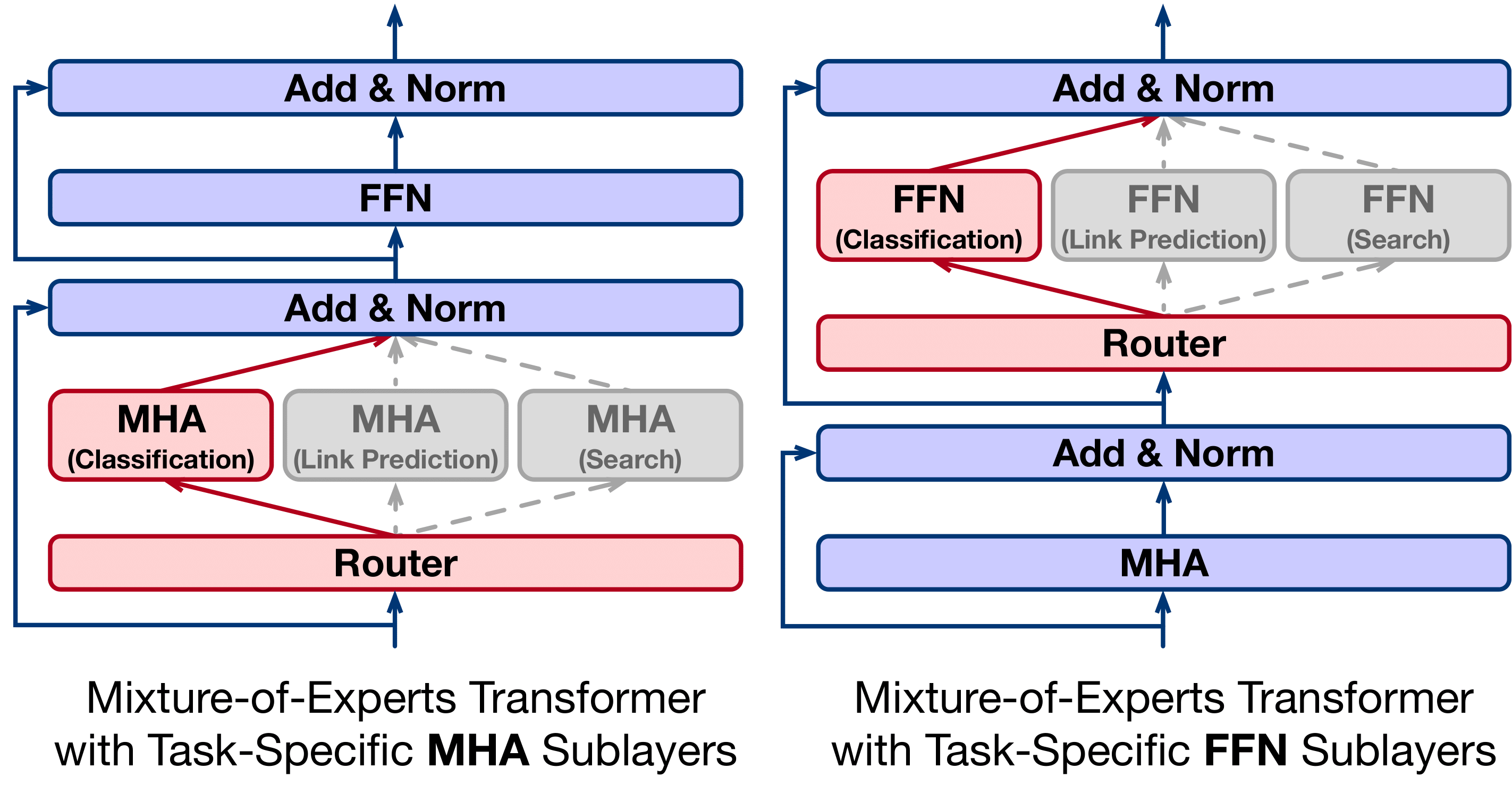
While multi-task learning is promising for improved parameter efficiency, sharing all parameters across tasks leads to undesirable task interference. To address this problem, we consider the Mixture-of-Experts Transformer architecture, which modifies the Transformer block in the language model to have multiple parallel sub-layers, each of which is dedicated for one task. When performing different tasks, the input will be routed to different sub-layers based on task types.
We conduct a comprehensive empirical study using datasets from multiple sources (e.g., MAPLE, SciDocs, SciRepEval, BEIR, and PMC-Patients) for evaluating various scientific literature understanding tasks. For each task, models will be tested on not only in-domain but also cross-domain evaluation datasets. Specifically, for extreme multi-label text classification, models trained on computer science and biomedicine papers will be tested in the geography and psychology fields; for link prediction, models trained on citation signals need to be evaluated on patient-to-patient matching and paper recommendation; for literature retrieval, models will be tested on datasets specific to COVID-19 or related to claim verification which are not seen during pre-training. Experimental results show that SciMult outperforms competitive scientific pre-trained language models on most datasets and achieves the new state-of-the-art performance on the PMC-Patients leaderboard.
The preprocessed evaluation datasets can be downloaded from here.
Disclaimer: The aggregate version is released under the ODC-By v1.0 License. By downloading this version you acknowledge that you have read and agreed to all the terms in this license. Similar to Tensorflow datasets or Hugging Face's datasets library, we just downloaded and prepared public datasets. We only distribute these datasets in a specific format, but we do not vouch for their quality or fairness, or claim that you have the license to use the dataset. It remains the user's responsibility to determine whether you as a user have permission to use the dataset under the dataset's license and to cite the right owner of the dataset.
More details about each constituent dataset can be found in our GitHub repository.
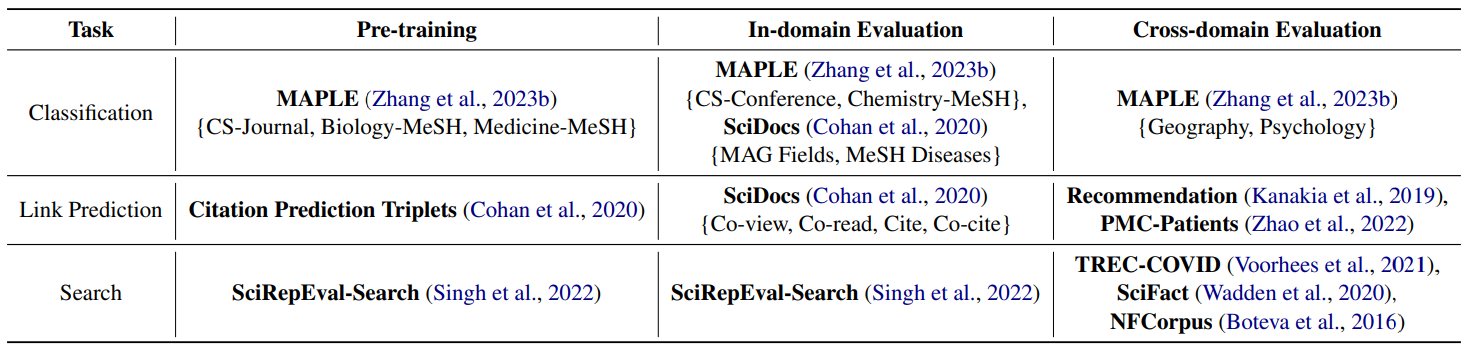
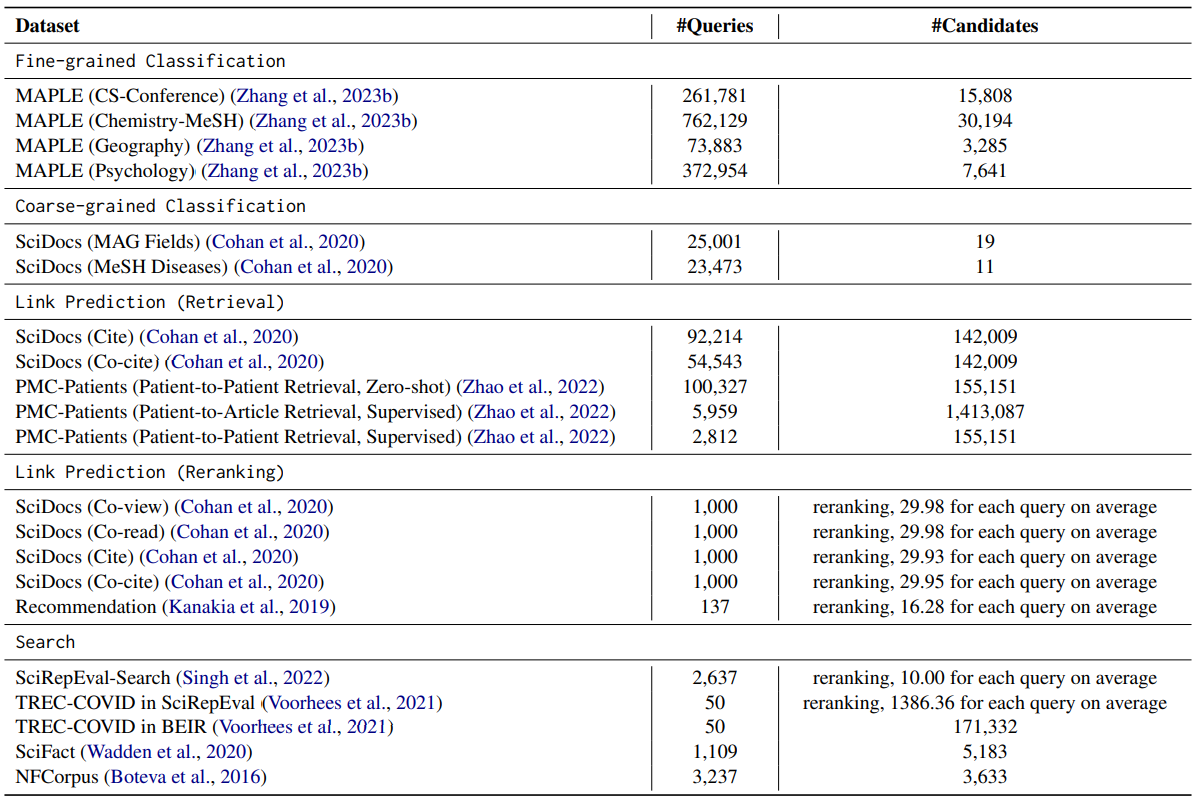
Comparisons between SciMult and state-of-the-art scientific pre-trained language models (e.g., SciBERT, PubMedBERT, SPECTER, SciNCL, and SPECTER 2.0) in each task.
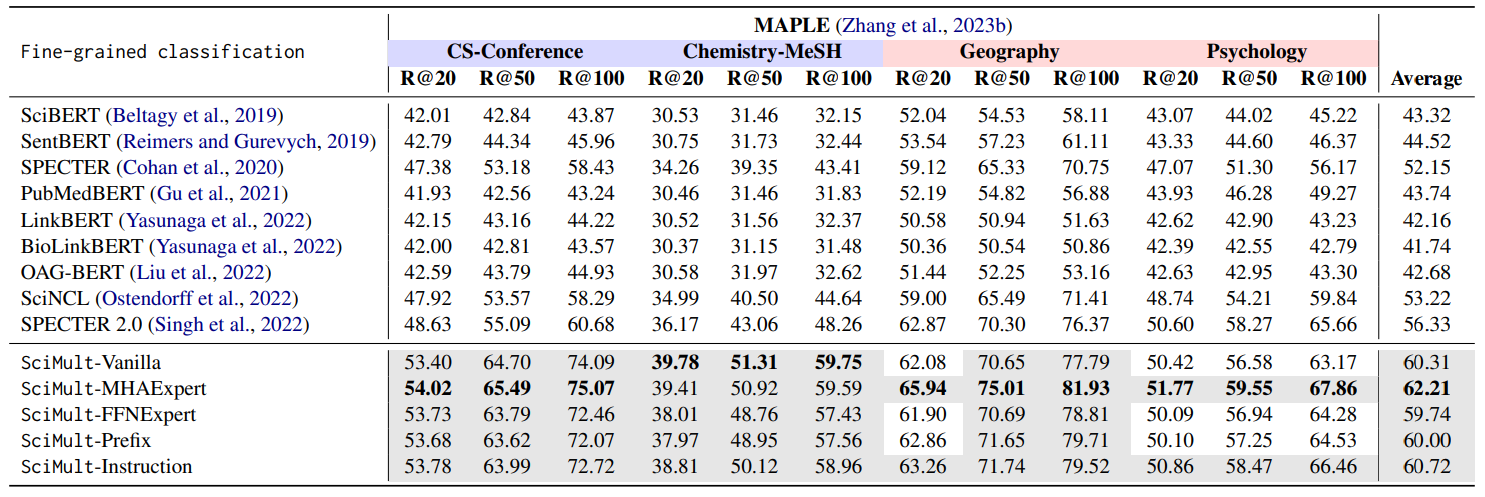
Fine-Grained Paper Classification
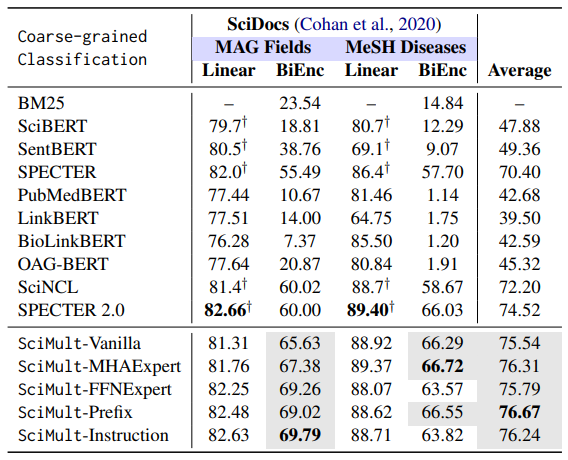
Coarse-Grained Paper Classification
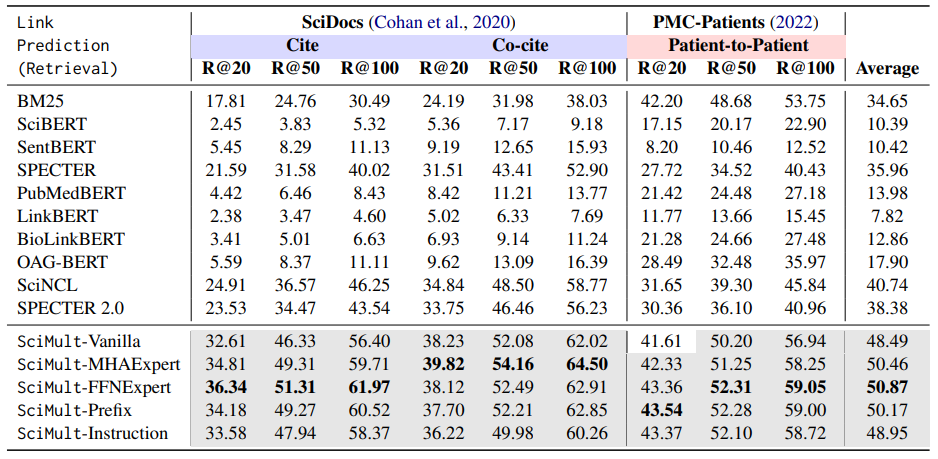
Link Prediction (Retrieval)
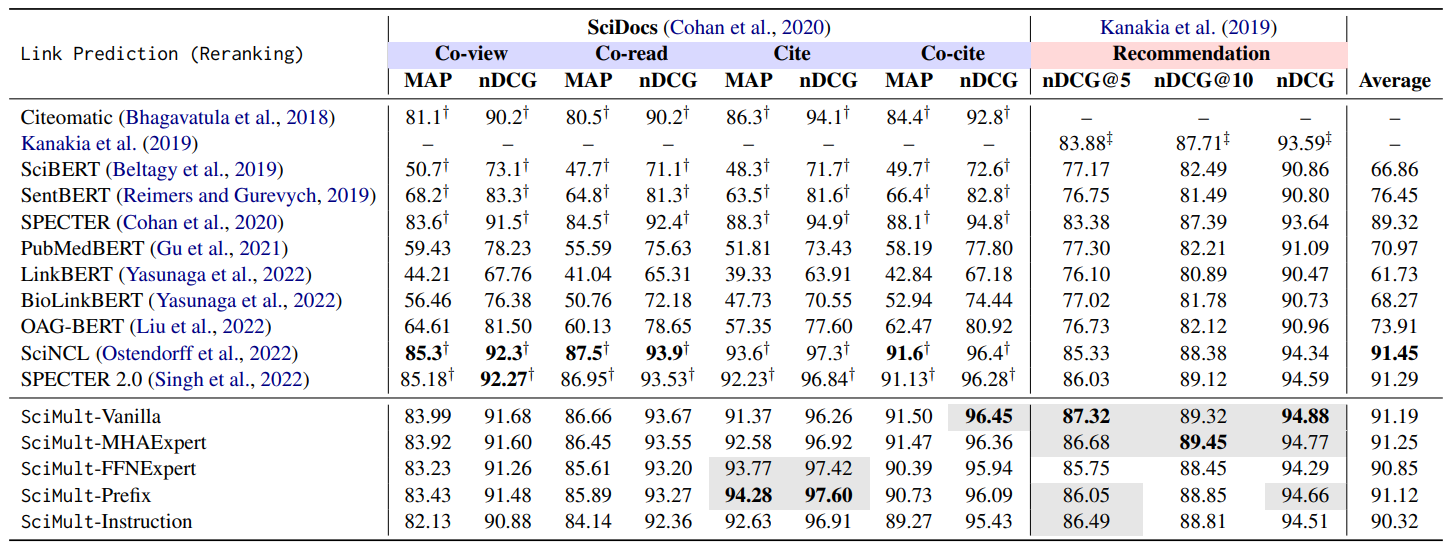
Link Prediction (Reranking)
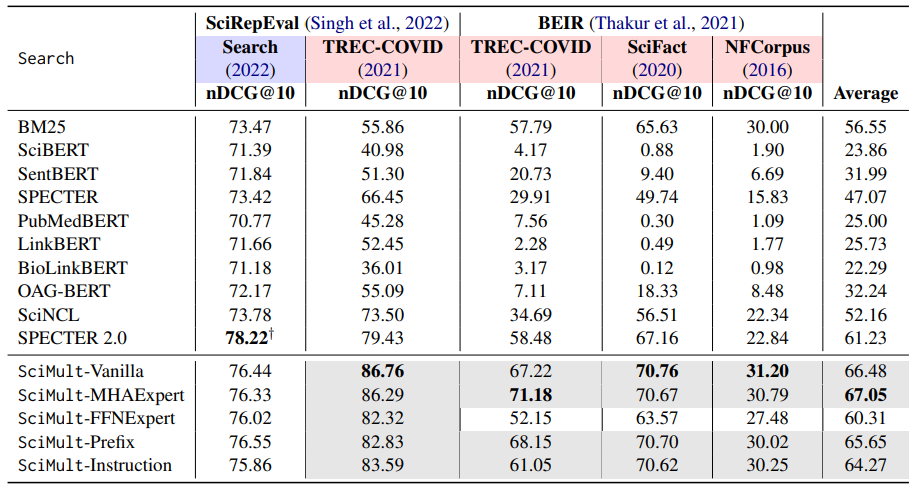
Literature Search
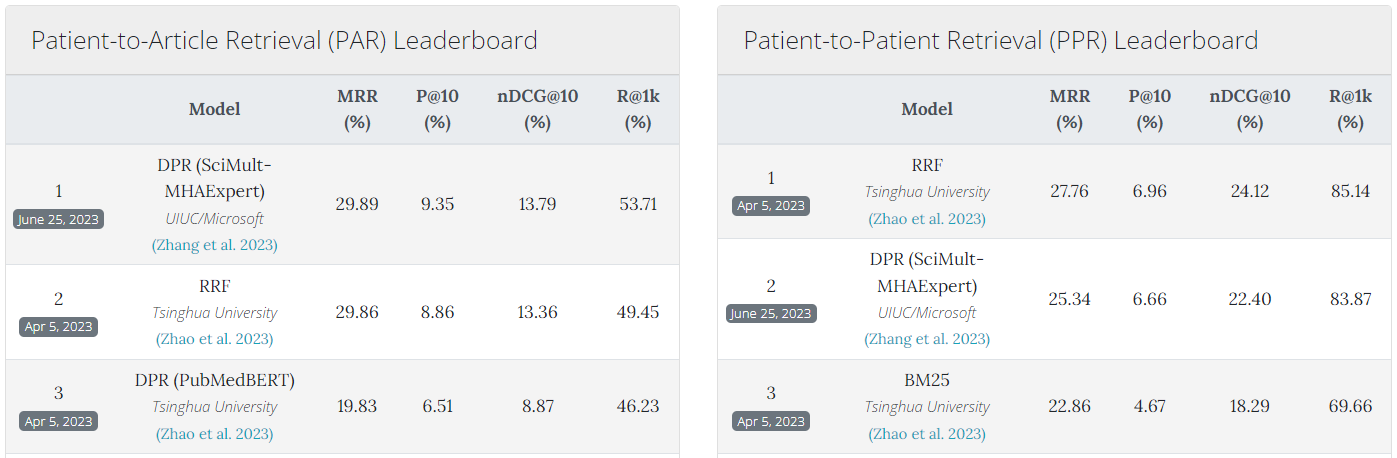
PMC-Patients Leaderboard
@inproceedings{zhang2023pre,
title={Pre-training Multi-task Contrastive Learning Models for Scientific Literature Understanding},
author={Zhang, Yu and Cheng, Hao and Shen, Zhihong and Liu, Xiaodong and Wang, Ye-Yi and Gao, Jianfeng},
booktitle={Findings of EMNLP'23},
pages={12259--12275},
year={2023}
}